What is Database Index?
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure.
Primary Index
Definition:
- A primary index is automatically created when a table has a primary key.
- It is typically a clustered index, meaning the actual row data is physically stored in the order of the primary key.
Characteristics:
- Unique: Enforces uniqueness.
- Sorted: Data is stored in sorted order of the primary key.
- Efficient for range and point queries on the primary key.
Example:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT
);Here, id is the primary index, and the table’s data is clustered/sorted by id.
Sparse Index
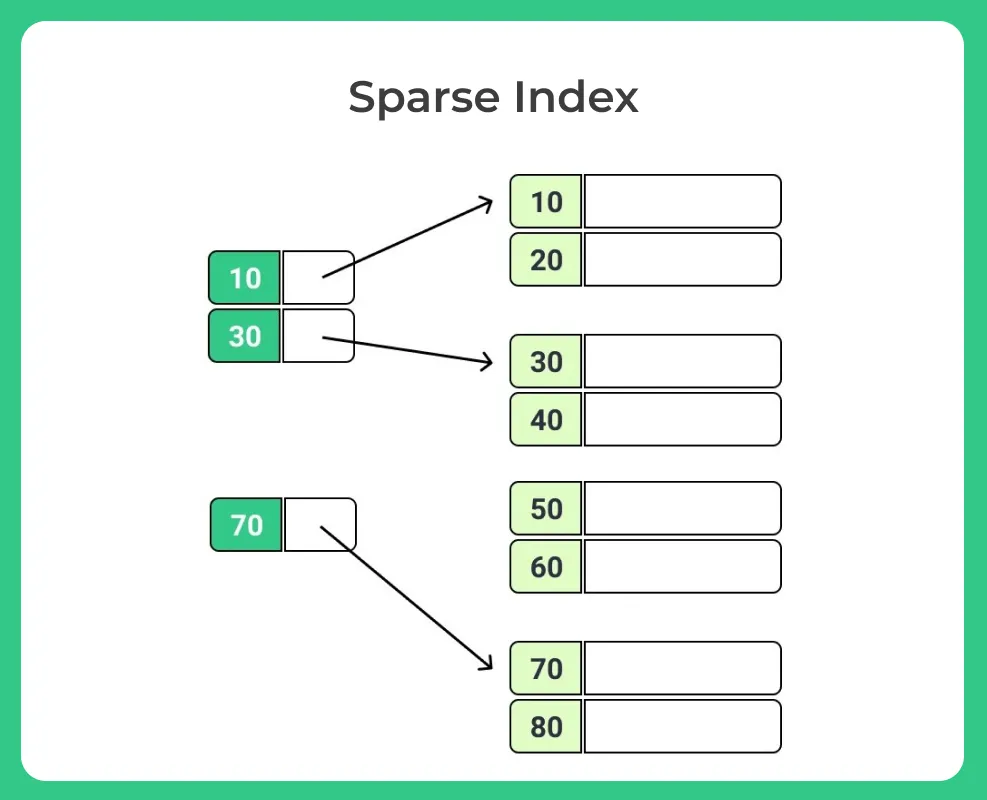
Definition:
- A sparse index only holds entries for some of the data blocks, not every record.
- Often points to the first record of each block.
How It Works:
If we have data like:
- Block 1: id 1, 2, 3
- Block 2: id 4, 5, 6
- Block 3: id 7, 8, 9
Then the index would look like:
Index: [1 → Block1, 4 → Block2, 7 → Block3]
Searching for id = 8:
- Find the closest index entry 8, which is 7.
- Go to Block 3 and scan within the block to find 8.
Pros:
- Smaller index size, less memory.
- Suitable when data is accessed block-wise or in ranges.
Cons:
- Not good for random access to single records, as scanning within a block is needed
Clustered Index
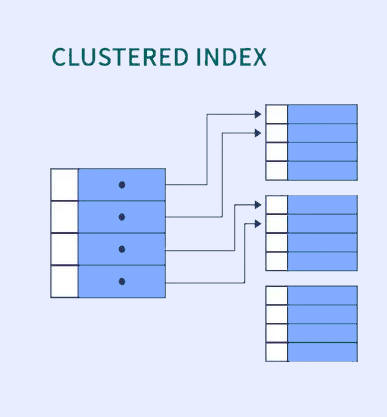
Definition:
- A clustered index determines the physical order of data in storage.
- Each table can have only one clustered index.
- In many DBMS like InnoDB (MySQL), the primary key is the clustered index by default.
Characteristics:
- The index contains the actual row data (not just a pointer).
- Range queries are fast due to sorted physical layout.
Comparison with Sparse Index:
- Clustered indexing means data is stored with the index.
- Sparse indexing means index points to the data blocks, and data is stored separately.
- Clustered index may look like a sparse index, but it’s integrated with the data.
Secondary Index
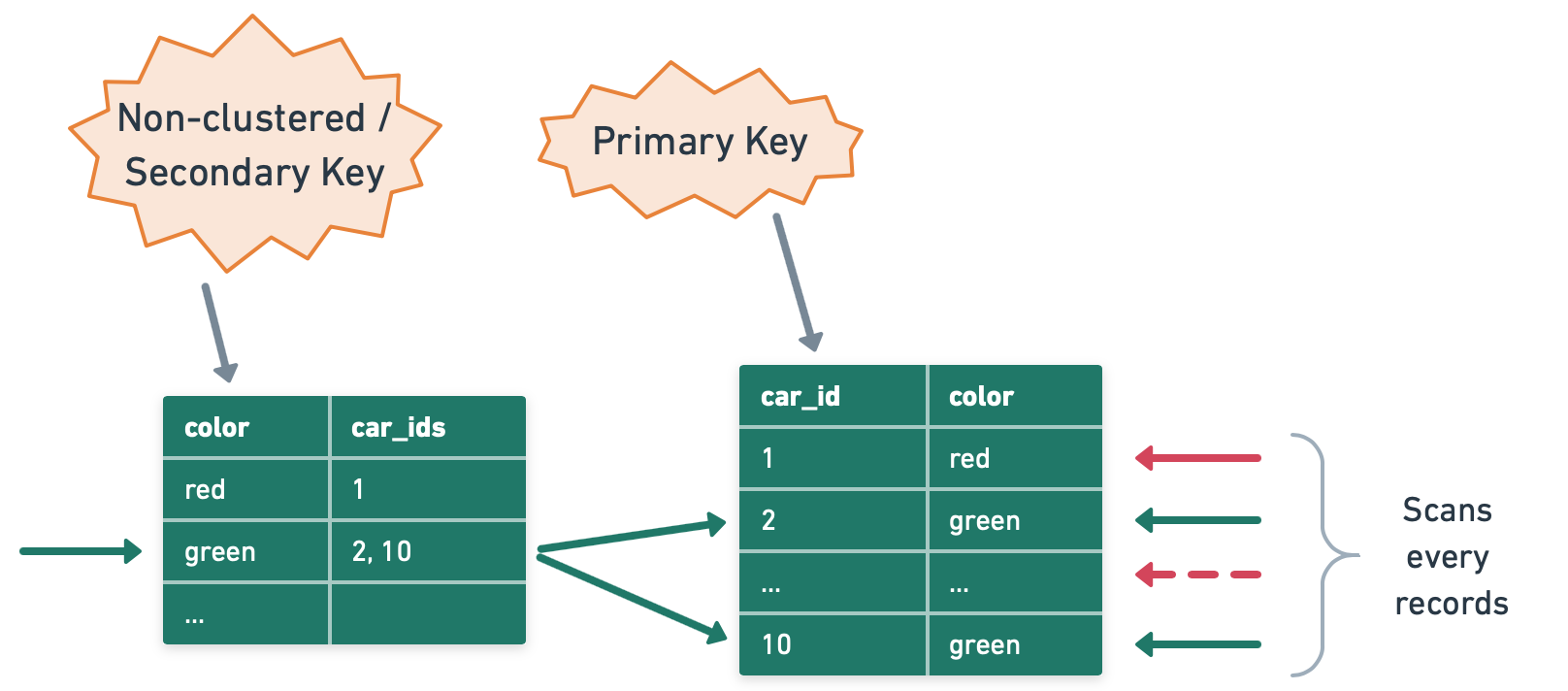
Definition:
- Any index not on the primary key is a secondary index.
- It stores the indexed column and a pointer to the primary key.
Structure:
Secondary index on name:
Index (name → id):
[Alice → 1, Bob → 2, Carl → 3]
To retrieve full row for name = 'Bob':
- Use secondary index → Get
id = 2. - Use primary index to locate full row with
id = 2.
This is called an index back lookup.
Performance:
- Slower than clustered index because it requires two lookups.
- But faster than scanning the whole table.
- Can be optimised using covering indexes.
Covering Index
CREATE INDEX idx_name_age ON users(name, age);Then,
SELECT age FROM users WHERE name = 'Bob';→ Fully answered by index. No back lookup needed.
Index Strategy in Production
When to Create Indexes:
- Based on traffic patterns: Analyze slow queries and frequent filters.
- Create indexes on:
- WHERE conditions
- JOIN columns
- ORDER BY fields (if sorting is frequent)
- GROUP BY fields
- Use composite indexes when queries use multiple columns together.
Avoid Over-indexing:
- Every index slows down INSERT/UPDATE/DELETE (because all indexes must be updated).
- Use only necessary indexes.
- Use monitoring tools (like EXPLAIN in MySQL/Postgres) to check query plans.
Example: If you have:
SELECT * FROM orders WHERE customer_id = ? AND status = 'PAID';Consider:
CREATE INDEX idx_customer_status ON orders(customer_id, status);